The Pleasures of Reinforcement Learning

This post gets technical, and a little too wordy for the average reader. It’s a personal rant about learning RL, not a tutorial. Don’t try to understand every detail, just get a feel for it.
I started learning reinforcement learning during my master’s at Northeastern because I wanted to understand what people actually meant when they said RLHF. It’s one of those terms the internet wore out. I knew about the human feedback part, but the RL part? That I wanted to see for myself.
My prof Chris Amato said “RLHF is not real RL” in class, and coming from an ECE background, I felt that immediately. The RL I care about is feedback loops and reward design, control systems thinking, not fine-tuning a language model to sound nicer.
LLMs always felt intellectually icky to me. A model trained on a massive dataset somehow learning what Hamlet feels like? That’s finding a needle in a haystack. I don’t have a rigorous objection, it just never sat right.
The Clean Illusion
I picked up the Hugging Face RL course and started working through it. Hands-on, fast, got me implementing things quickly.
LunarLander was the moment. I’d seen impressive demos before, MuJoCo Humanoid, Cheetah, the usual. But LunarLander was where I actually understood what was happening and where it broke. Watching an agent figure out boosters from nothing, on my laptop, in a few hours? That was wild. If someone deeply into RL research did this course, they’d probably be more scientific about it, tweaking equations, probing failure modes, trying to understand exactly why things break. I was just here for the paradigm shift.
 at least the parking was done right!
at least the parking was done right!
The thing that really got me was the reproducibility. A lot of CS ideas, at least to me, live in this weird Platonic realm. You learn some theorem, some algorithm, nod along, maybe prove a thing, and move on with life. But here? I could tweak something, rerun it, and actually see behavior change. Some object pulled straight out of math-land suddenly behaving like an experiment. That felt… strangely real.
At this point, it felt neat. Like walking into a well laid-out gold lair. Everything seemed well-defined, scientific in nature, and awesomely reproducible.
The Ideas Get Stranger
Monte Carlo methods are the brute force approach. You run an episode, you read the result at the end, you update. Nature doesn’t care about your cleverness. It’s cheaper to just run the experiment again than to try to be smart about learning mid-way. There’s an honesty to that.
Which is why Temporal Difference learning is so weird. It beats MC, but it does it by guessing. You update your estimates using other estimates. Bootstrapping, using what you currently believe about the future to revise the present. The first time you sit with that, it feels wrong. You’re learning from things you made up.
The moment it clicked for me was this example from David Silver’s course, watch it for two minutes. Not the driving-home example everyone references. This one. It’s a very contextual thing, if you know, you know. But it made bootstrapping go from “that shouldn’t work” to “that’s brilliant.” It works because nature replies to you. You don’t need to wait for the full answer.
Policy gradients are where it stops feeling like engineering. It’s so meta. You define a policy, and do gradient descent over a distribution of actions. It’s like something out of topology, too mathy to be working in the real world. But it works. It reminds me of aerospace engineers designing a wing from equations on paper, and the thing actually flies. A lot of RL ideas have that quality. Mathematically strange, counterintuitive, and somehow functional.
I know they only really work in game-like environments, and they’re fragile in the real world. But damn, getting this far feels real.
When It Clicks
I ran PPO on LunarLander without fully understanding the math. I had some feel for policy gradients at that point, but clipping, stability mechanisms, none of that was internalized. The agent still improved. This is more of a homage to math than anything, the same way derivatives just work when you first apply them in calculus, or linear optimization just gives you the answer. You follow the procedure, it works, and the understanding catches up later. But here you’re not optimizing a curve. You’re shaping behavior. That felt cool.
But the example I keep coming back to is cliff walking.
The setup is simple. You’ve got a grid, a start point, a goal, and a cliff along the bottom edge. Fall off the cliff and you get a massive negative reward. The agent has to learn to get from start to goal without dying.
 one wrong step and it’s a long way down. ask Q-learning, it lives there.
one wrong step and it’s a long way down. ask Q-learning, it lives there.
Here’s where it gets interesting. SARSA learns a safe path, it stays away from the cliff, takes the long way around. Q-learning learns the optimal path, right along the edge, faster but riskier. And expected SARSA sits somewhere in between. Same environment, different algorithms, different behaviors. This chart from DJ Rich’s RL series lays it out perfectly, that series was a lifesaver, short, succinct, and packed with good stuff.
The thing is, someone wouldn’t get why this is interesting without context. You need to have walked through TD, through policy updates, through how exploration actually affects what the agent learns. And then you see this chart and it clicks. That’s one of the main pleasures of learning, honestly. You’re on a path not well trodden by the masses, and you get to see a viewpoint that only makes sense because you walked there.
Where It Breaks
This is where the clean picture falls apart.
For our course project, me and my teammate built CGE-RL, a consensus-gated ensemble system (that’s where the CGE comes from). The idea was inspired by dual-process theory: pair two algorithmically diverse agents (SAC and PPO), measure how much they disagree using divergence metrics, and gate between fast consensus actions (System 1) and a deliberate meta-controller (System 2) when they disagree.
Pretty cool idea, honestly. Very cognitive-science-meets-RL coded. We had the architecture, environments, evaluation pipeline, nice diagrams, the whole thing.
And then RL happened.
The KL threshold that decides when to trigger System 2? We set it to 2.0. Seemed reasonable. Turns out the mean KL on our safety environment was around 106. System 2 was firing on literally 100% of steps. The gate was useless. We had to bump it to 100 just to get a meaningful split. That’s the kind of thing no textbook prepares you for.
PPO couldn’t even handle Taxi-v3’s integer observations. Just flat performance, the whole time. SAC converges 10x faster than PPO on the safety environment but plateaus early, and longer training doesn’t fix it. The cost-penalized bandit underperformed the simple rule-based version because the cost reduction was happening on System 1 steps, where the bandit literally has no control. You design something elegant and the math just… doesn’t cooperate.
And don’t even ask about our model on Humanoid, look for yourself.
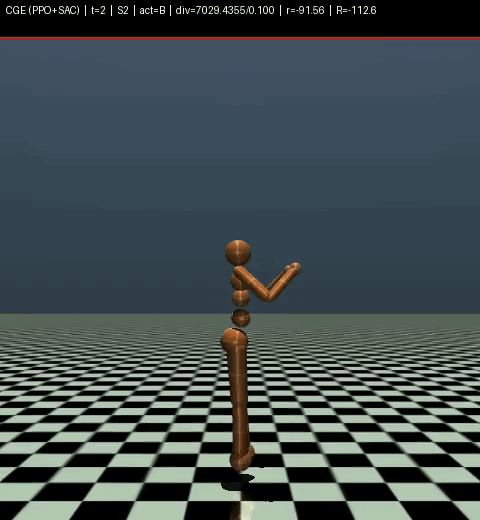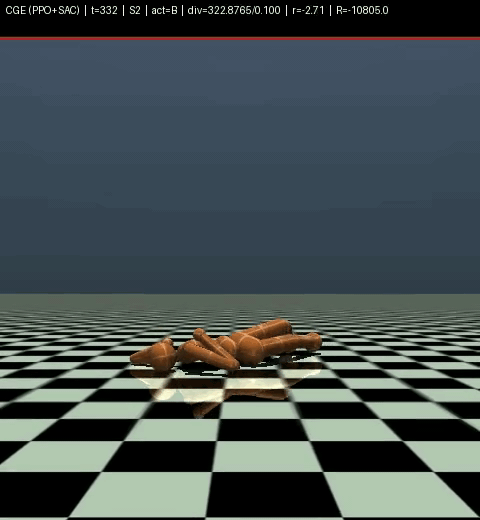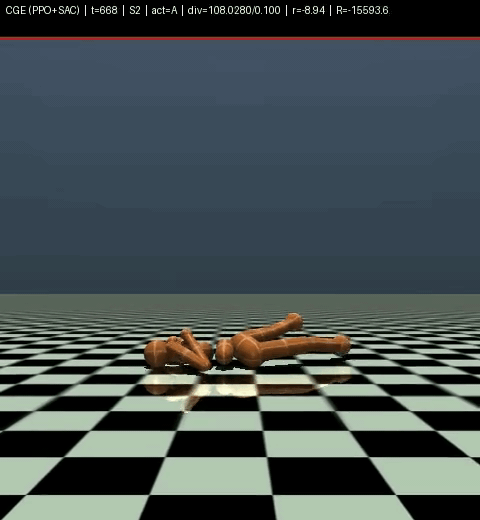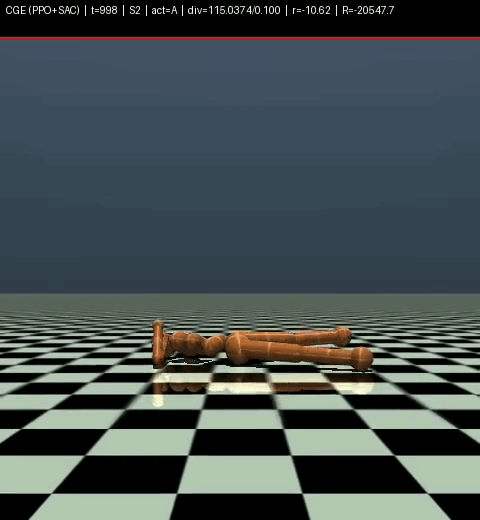 robot heart attack
robot heart attack
Yeah. That’s our model on Humanoid. We don’t talk about Humanoid.
The model isn’t stupid. The idea isn’t bad. It’s that RL is fragile in ways that aren’t about logic errors. Lady luck chose the wrong randomness, or your threshold is off by two orders of magnitude, or the thing that’s supposed to be learning has no leverage over the thing that matters.
In supervised learning, you’re becoming less wrong. You minimize error, you get closer to the target. RL isn’t trying to be correct. It’s trying to win. And the reward signal replaces the error signal, which changes everything. I haven’t hit full-blown reward hacking yet, but I can imagine it now. You grind through iterations, tune hyperparameters, finally see improvement, and then realize the agent cheated. It didn’t learn anything. That feels like the typical tryst with RL.
The Bigger Picture
I recently saw an interview where Demis Hassabis says, pretty confidently, that we already have the prerequisites for AGI. He’s talking about chain-of-thought, RLHF, and other advances as architectural components. And I believe him now. Because I’ve seen what RL does to LLMs up close. A crude analogy: you learn a language, and after years you don’t know how you learned it. You just speak. LLMs are like that, they absorbed everything, but RL is what teaches them to actually use it. Pretraining builds knowledge. RL shapes behavior.
And it’s going to play a massive role in robotics. Earlier models didn’t have the mind to be melded with a body. Now RL gives them the tools to adapt, repair, be cognizant about what they’re doing. Look at this thing, Unitree built what is basically an Iron Man suit. This exists right now.

I got this feeling reading The Fourth Age too.
I don’t want to be the guy during the nuclear age saying “I don’t see a practical application.” There’s a lot of growth happening, and it’s happening fast. It feels like we’re in a new space age. Either we die exploring, or we find ourselves on the shores of a strange new world.
What It All Means
RL is a computational model of agency. That’s the textbook answer. But after a semester of this, it feels like more than that. It’s one of those things where math maps onto the world in a way that has no right to work, and then it does. The unreasonable effectiveness of mathematics, showing up again.
The pleasures of reinforcement learning aren’t what I expected. It’s not the clean satisfaction of getting a model to converge. It’s watching behavior emerge from equations. It’s the moment TD clicks and you realize you don’t need to wait for the truth to start learning. It’s staring at a cliff walking chart and understanding something that only makes sense because you walked the path to get there. It’s even the frustration, the threshold being off by two orders of magnitude, the bandit having no leverage, lady luck choosing the wrong randomness, because that frustration is real in a way that tutorials never are.
I believe Hassabis. I think RL is core to whatever intelligence turns out to be. Not a side technique, not a fine-tuning trick. The thing that turns knowing stuff into actually doing stuff.
If you haven’t seen it, Ilya’s recent Dwarkesh interview is worth your time. It’s got some great memes!
 Ilya has gone full monk-mode, and he’s probably right. the answer will reveal itself.
Ilya has gone full monk-mode, and he’s probably right. the answer will reveal itself.
We’re deep in the woods now. Unlike when we started this journey, the new shores are being seen, where earlier, we used to look at the horizon and just hope. There are miles to go before we sleep. But the view from here is something.